Spark重新分区Repartition
在分布式环境中,数据合理分布是提高性能的关键因素。在SparkSQL的DataFrame API中有一个*repartition()*函数用于控制数据在Spark集群上分布。然而高效地使用这个函数并不容易因为改变数据分布就意味着集群节点间物理数据移动(即Shuffle)的损耗。
根据经验来看,使用repartition消耗较大因为该操作会导致shuffle。这篇文章中我们将更加深入的探讨在某些情景下,在合适的位置增加一个shuffle并移除其他两个shuffle会使整体执行更加高效。我们先来了解一些概念来理解关于数据分布的信息在Spark SQL中是如何内部利用的,然后再介绍一些使用repartition的实际示例。
本篇文章中提到的概念基于Spark源代码,版本为snapshot3.1,大多数概念也适用于先前的版本2.x。并且这些理论和内部行为对语言是透明的,跟我们用Scala,Java或者是Python API使用无关。
查询计划Query Plan
Spark SQL的DataFrame API允许用户实现高级transfomations,这些transformations是惰性的,这意味着它们不会立即执行而是在引擎上被转换成一个查询计划。当用户调用一个需要输出结果的action时,查询计划才会被具体化,比如我们正在把transformation的结果保存到一些存储系统中。查询计划本身可以被分为两种类型:一个逻辑计划和一个物理计划。查询计划执行的过程取决于逻辑计划与物理计划。
逻辑计划Logical Plan
逻辑计划这个词代表着一个逻辑计划执行的多个步骤,逻辑计划本身就是一个查询的抽象表示,它是一个树形结构,树中的每个节点表示一个相关的操作。逻辑计划本身不会包括任何有关执行的具体信息或者用来计算转换Transformation的算法如聚合aggregation。它仅用一种方便优化的方式来表示查询的信息。
在逻辑计划期间,查询计划会被Spark优化器进行优化,优化器会运用一系列用来转化计划的规则,这些规则大多数基于启发式,举个例子来说,在执行其他操作之前先对数据进行过滤是更好的(会减少内存占用)等等。
物理计划Physical Plan
一旦逻辑计划被优化完成,物理计划就开始了。物理计划的作用是把逻辑计划转变为可以执行的物理执行计划。不想逻辑计划那样抽象,物理计划会表示很多有关执行的具体细节信息,因为它包括了执行期间需要用到的具体算法。
物理计划也由两步组成因为物理计划有两个版本:spark plan和executed plan。Spark plan也称作策略,逻辑计划中的每个节点会在spark plan中转换成一个或者多个操作。一个策略的例子是JoinSelection,spark会决定使用哪种算法来join数据。spark plan可以通过api来查看,如Scala中:
1 | |
在spark plan创建之后,还有一组其他的规则需要应用以创建最终的物理计划的版本,即executed plan。Executed plan将会执行生成RDD代码,查看executed plan我们可以简单地在DataFrame上调用explain,因为它实际上就是物理计划的最终版本。另外我们也可以去Spark UI上查看图形表示。
EnsureRequirement(ER规则)
将Spark plan转换成Executed plan的这组规则称作EnsureRequirement,这组规则需要确保数据被正确的分配,因为有些转换需要保证数据被正确分配如joins和aggregation。物理计划中的每个操作符都有两个重要的属性:outputPartitioning和outputOrdering,这两个属性携带着数据分布的信息,以及在给定时刻数据如何被分区和排序的。除了这些,每个操作还有两个其他属性:requiredChildDistribution和requiredChildOrdering,节点通过这两个属性对其子节点的outputPartitioning和outputOrdering值提出要求。某些操作不会有任何需求但是有些操作需要,比如SortMergeJoin,这个操作对于其子节点有很强的要求,它要求数据必须以joining key进行分区和排序,这样才能正确的merge。让我们来考虑一个join两个表的简单查询(这两个表都是基于文件的数据源,格式为parquet):
1 | |
这个查询的spark plan看起来像下面这样:
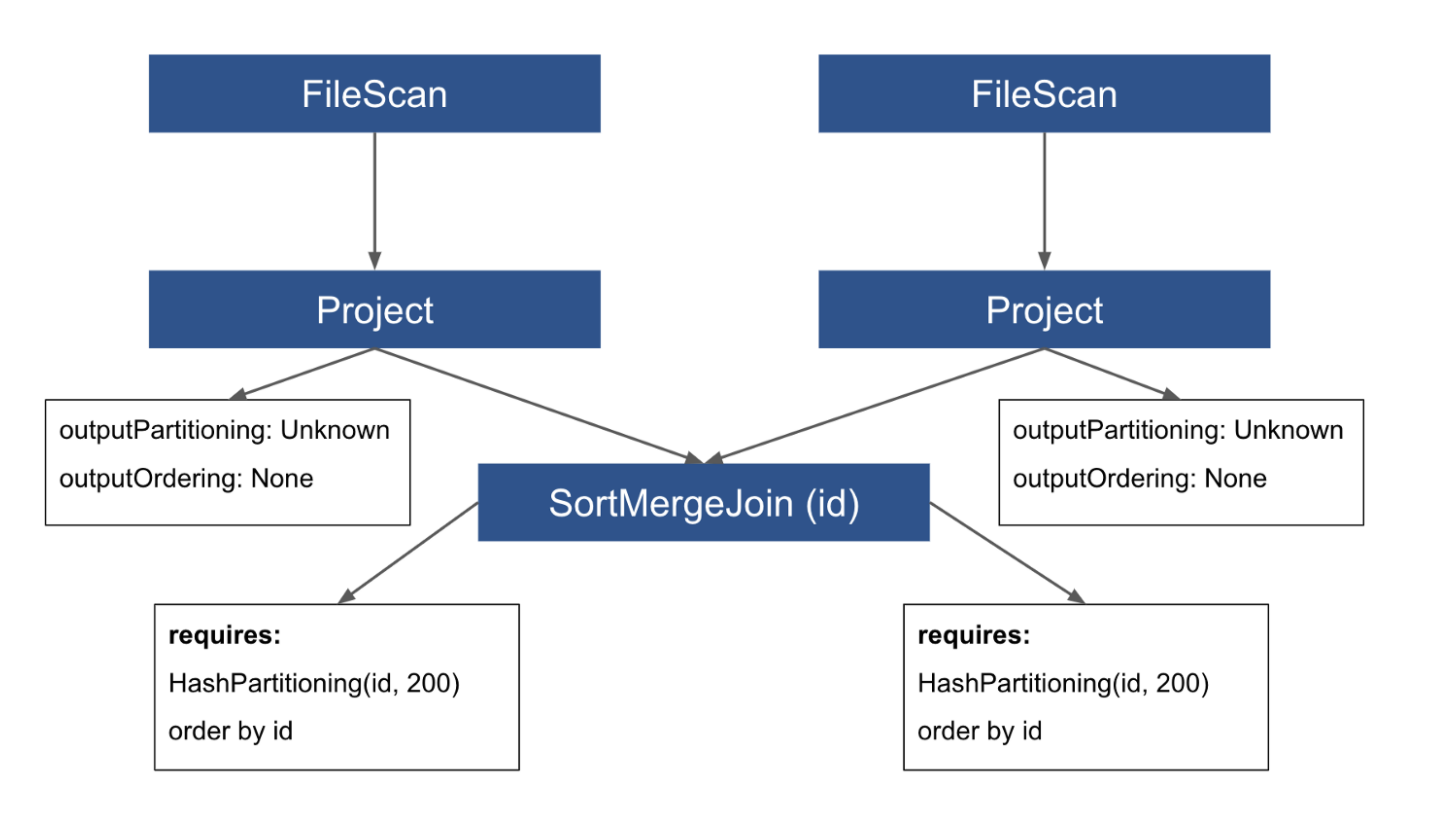
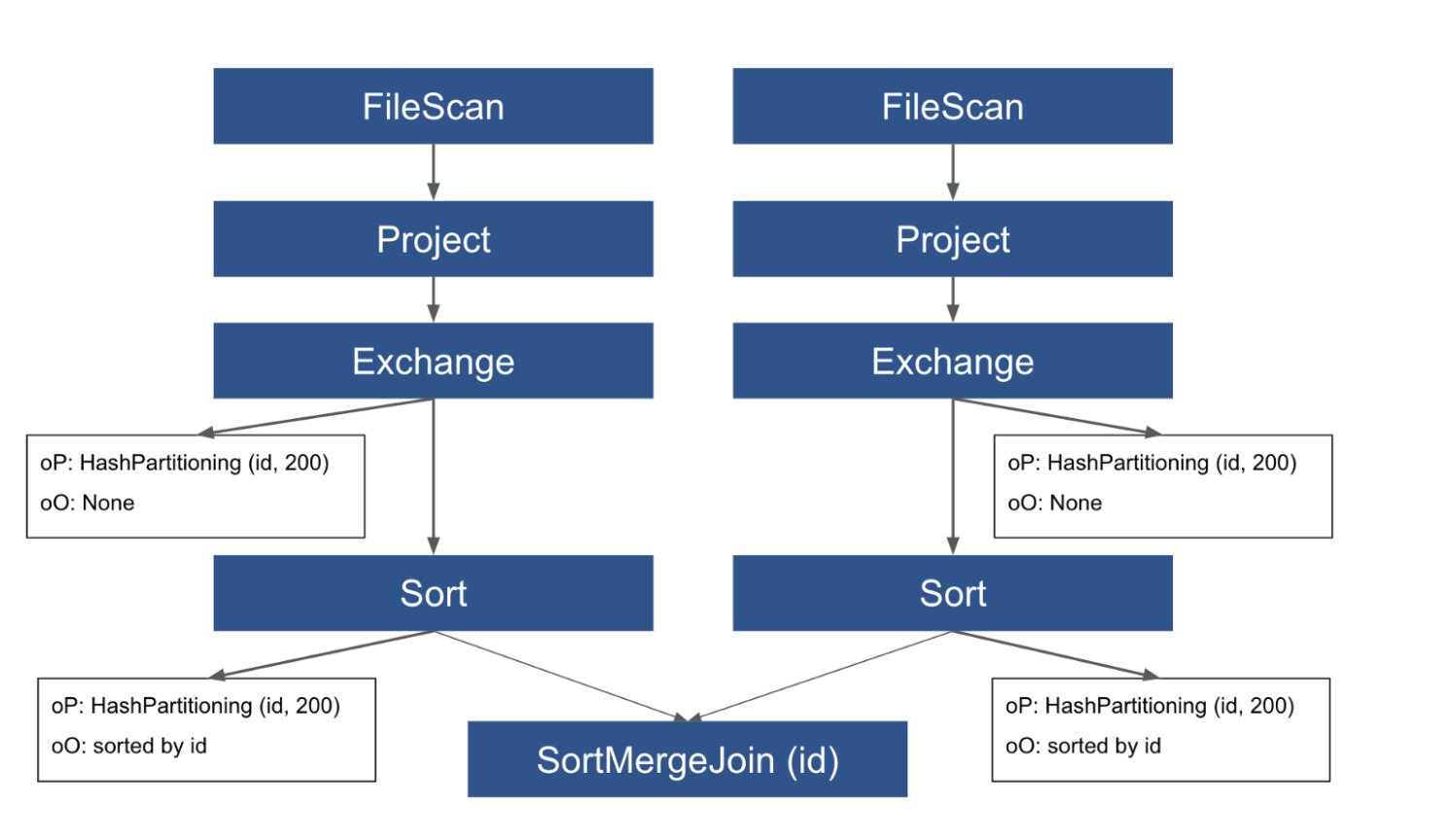
从spark plan中可以看到SortMergeJoin的子节点(两个Project操作)没有outputPartitioning和outputOrdering并且这是数据还没有提前重新分区和表未被分桶的常见情况。当ER规则应用于这个spark plan时会发现SortMergeJoin的需求没有满足,所有它将在这个计划上进行全部交换Exchange和排序Sort来满足需求。交换操作负责对数据重新分区以满足requiredChildDistribution需求,排序操作负责对数据进行排序来满足requiredChildOrdering,所以最终的执行计划看上去像下图所示(这个也可以在Spark UI上查看,但是不会看到spark plan因为到这一步时它已经不存在了)
分桶
如果两个表都根据joining key分桶了那么情况将有所不同。分桶是一种将数据存储在预shuffle和可能的预排序状态的技术,其中bucket的信息存储在megastore中。在上述例子中,如果每个桶中有一个确定的文件,FileScan操作会根据metastore中的信息获取outputPartitioning设置,outputOrdering也会被设置并且会被传递给下游Project。如果两个表根据joining key被分桶到相同数量的桶中,那么有关outputOrdering的需求就会被满足,ER规则将不会在spark plan上执行交换操作。join两侧的相同分区数在这里至关重要,如果这些数据不同,exchange操作会在每个与默认分区数不同的分支上执行一遍,默认spark.sql.shuffle.partitions=200。所以合适正确的分桶可以让join操作进行shuffle。
需要理解的重要一点是,Spark需要了解分布才能使用它,所以即使你的数据使用分桶进行了预shuffle,除非你将数据作为表来读取以从megastore中获取信息,否则spark不会知道这些信息所以不会在FileScan上设置outputPartitioning。
Repartition
正如文章开始提到的,repartition函数可以用来改变数据在spark集群上的分配。这个函数将数据应该被分布的列作为参数列(可选项是第一个参数可以指定要被分区的数量)。引擎上发生的事情是,它将一个RepartitionByExpression节点添加到逻辑计划中,然后使用策略将其转换为Spark plan中的exchange,并将outputPartitioning设置为HashPartitioning,hash键是用作参数的列名。
repartition函数另一种使用是仅指定一个参数,就是要被重新分区的数量,这种方式数据将会随机分布。