Hadoop之Hdfs
Hdfs介绍
Hdfs中数据块block的设计
block大小设置
Hdfs中的文件在物理上以块block的形式存储,块的大小可以通过参数进行配置(dfs.blocksize),hadoop2.x版本中默认块大小为128M,之前版本为64M。
block大小设置的原则是最小化寻址开销,减少网络传输。
- 设置合适的block大小有助于减少磁盘寻址时间,提高系统吞吐量;
- NameNode需要在内存FSImage文件中记录DataNode中数据块信息,如果block size太小,需要维护的数据块信息增多,内存消耗增加;
- 若Map任务奔溃,重新启动加载数据是,block越大,数据加载时间越长,恢复任务慢;
- 主节点监控其他节点,每个节点会周期性的报告自己的工作状态,若节点超过时间阈值未报告则主节点视该节点下线,并将该节点的数据分发给其他节点。而时间阈值根据block size进行估算,若size设置不合理,容易误判节点死亡;
- MapReduce中map任务通常一次只处理一个block中的数据,若block设置过大会导致任务数量太少导致运行速度过慢;
- 读写需要数据的网络传输,block过大网络传输时间过长导致程序超时无响应,任务执行过程中拉取其他节点的block或失败重试的成本太高;block过小则会频繁的进行文件传输,增加对网络和CPU的占用;
Hdfs架构
NameNode
- 负责文件元数据信息的操作以及处理客户端的请求;
- 管理Hdfs文件系统的命名空间NameSpace;
- 维护文件系统树FileSystem以及文件树中所有的文件和文件夹的元数据Metadata,维护文件到块的对应关系和block到节点的对应关系;
- 维护镜像文件fsimage和操作文件editlog,一般缓存在内存中也可持久化到磁盘;
- 记录文件中各个block所在的DataNode的位置信息,这些信息不会永久保存,在NameNode启动时,DataNode在向NameNode进行注册时进行缓存;
DataNode
- 负责管理其节点上存储数据的读写,定期向NameNode发送心跳和文件块状态报告等
Secondary NameNode
NameNode启动时会生成整个文件系统的快照fsimage,启动后文件的改动信息记录在editlog(写过程由DataNode触发,当DataNode写文件操作后,与NameNode进行通信,告诉NameNode改文件的block信息,NameNode将这些信息保存在editlog中),当NameNode重启时,editlog合并到fsimage中生成最新的系统快照。
这种运行逻辑存在问题:
- NameNode长时间不重启,editlog会变得很大;
- NameNode的重启会因为太大的editlog要合并到fsimage中而变得很慢;
- NameNode挂掉,editlog丢失,而fsimage的版本太旧导致中间数据丢失。
于是增加Secondary NameNode来解决上述问题,其职责为定时查询NameNode上的editlog并将其合并到自己的fsimage中,合并完成后将新的fsimage拷贝到NameNode上进行替换。
HA设计
Hadoop1.x 中只有一个NameNode,存在单点问题,即NameNode挂了后集群不可用。2.x中提供两种方式实现高可用:NFS(Network File System) 和 JN(JournalNode,Quorum Journal Manager)。
实现思路
集群中有两个NameNode,一个为Active NameNode,另一个为Standby NameNode,这两个NameNode状态可以切换,但是只能存在一个Active NameNode,且只有Active NameNode对外提供服务而Standby NameNode不提供服务。两种NameNode之间通过NFS或JN进行editlog同步。
Active NameNode更新editlog后将其上传NFS或者JN,Standby NameNode定时从NFS或JN上读取editlog,然后合并至fsimage上生成最新的fsimage,合并完成后通知Active NameNode获取新的fsimage进行替换。
所以Active NameNode和Standby NameNode上的fsimage都是最新的,当Active NameNode挂了,可以直接将Standby NameNode切换为Active NameNode。
- NFS:一个共享的文件存储系统,Active NameNode写文件, Standby NameNode读文件,一旦不可用则数据无法继续同步。
- JN(Quorum Journal Manager): JournalNode集群,由2N+1个节点组成,最多可容忍N个节点挂掉,保证editlog日志文件共享存储系统的可用性。
架构图
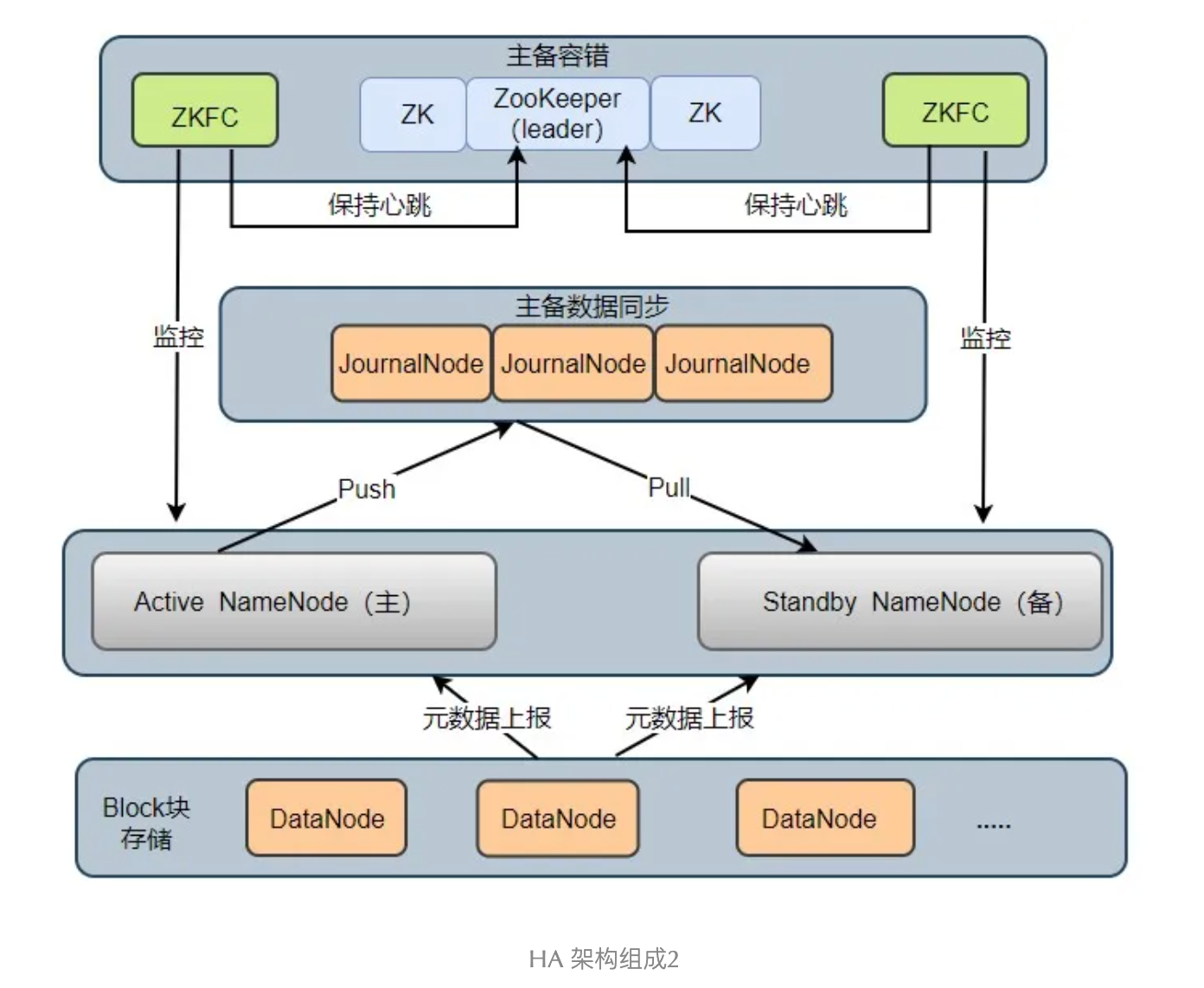
由上图可以看出,NameNode的主备监控由ZKFC(ZKFailoverController)完成,ZKFC时独立运行的进程,每个ZKFC监控一个NameNode,当监控主节点的ZKFC发现主节点异常时,该ZKFC端开与ZooKeeper的连接,释放分布式锁,监控备用NameNode的ZKFC抢到锁并将其监控的Standby NameNode切换成Active NameNode。
ZooKeeper为ZKFC实现故障转移提供统一协调服务。通过ZooKeeper中watcher的监听机制,通知ZKFC异常NameNode下线并保证同一时刻只有一个Active NameNode。
主备切换流程
Hdfs集群刚启动时,NameNode节点状态都是Standby,之后每个NameNode节点都会启动ZKFC进程后去ZooKeeper集群抢占分布式锁,成功抢占分布式锁的NameNode会成为Active NameNode,之后ZKFC实时监控自己的NameNode。
Hdfs提供两种HA状态方式:
一种是管理员运行命令 “DFSHAAdmin -failover”执行状态切换;另一种是自动切换。
Active NameNode挂掉后,Standby NameNode如何升级?
Active NameNode挂掉后,对应的ZKFC进程检测到NameNode状态,向ZooKeeper发生删除锁的命令,锁删除后,触发一个事件回调Standby NameNode上的ZKFC。ZKFC收到消息后先去ZooKeeper抢锁,锁创建完成后会检查原来的主NameNode是否真的挂掉(排除其网络延迟等),确认挂掉则升级当前节点为Active NameNode;若没挂掉则先将原来的主节点降级为备节点,将当前节点升级为Active NameNode。Active NameNode上的ZKFC进行挂掉而Active NameNode正常,如何切换?
ZKFC挂掉后,ZKFC与ZooKeeper之间的TCP连接断开,session消失锁被释放,触发事件回调Standby NameNode上的ZKFC进程,ZKFC去抢占锁,抢锁成功后与上述执行过程一致。
Hdfs读数据流程
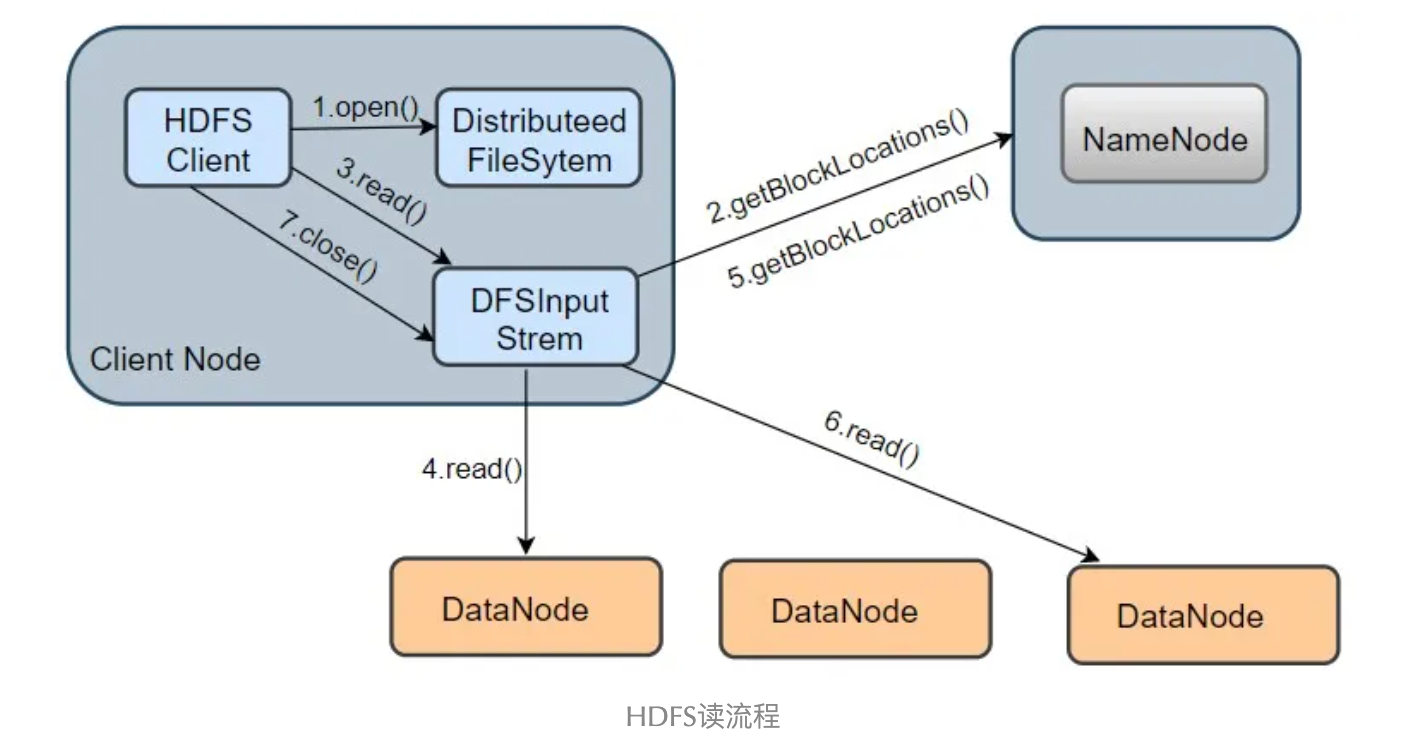
- 打开文件:客户端调用*DistribuedFileSystem.open()方法打开文件,该方法中调用DFSclient.open()*方法得到DFSInputStream对象用于读取数据块
- 构造DFSInputStream:*DFScliernt.open()构造DFSInputStream输出流时,调用getBlockLocations()*方法向NameNode节点获取组成文件的block位置信息,且block的位置信息按与客户端距离的远近排序
- 连接DataNode读取数据块:客户端通过调用*DFSInputStream.read()方法,连接到离客户端最近的一个DataNode读取block,数据会以数据包packet(注:client向DataNode或DataNode pipline之间传输数据的基本单位,默认64kb)为单位从DataNode通过流式接口传给客户端直到一个数据块读取完成;DFSInputStream会再次调用getBlockLocations()*方法,获取下一个最优节点上数据块的位置
- 文件的所有block读取完成,调用close()方法,关闭输入流,释放资源
Hdfs写数据流程
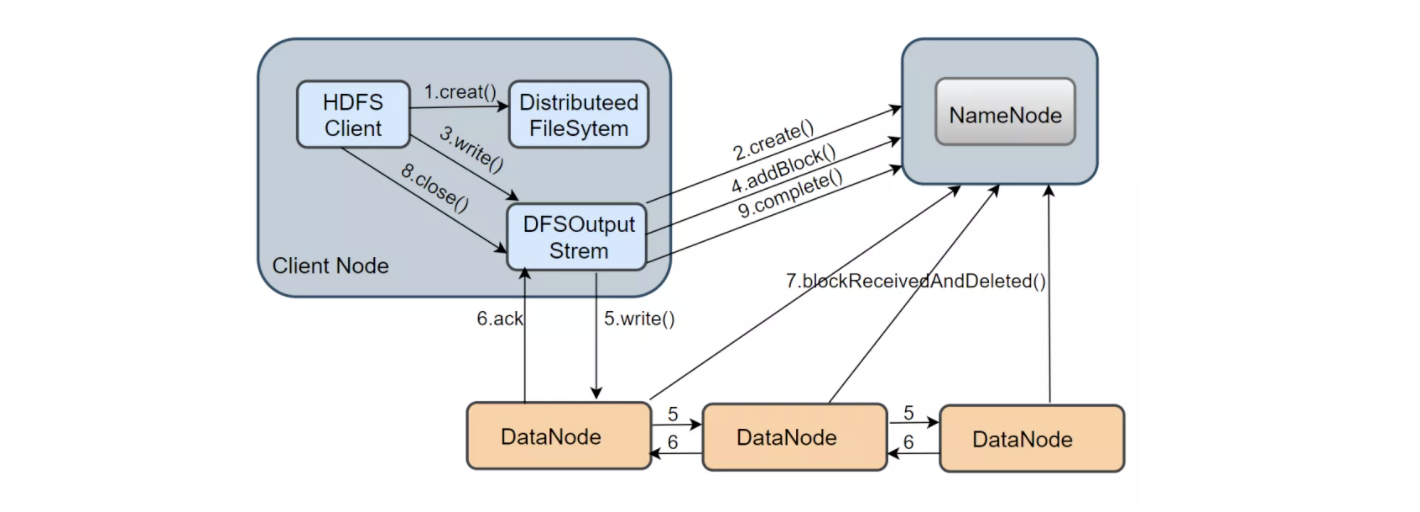
- 在NameNode创建文件:当client写新文件时,调用*DistributedFileSystem.create()*方法,该方法中会生成一个DFSOutputStream对象,生成该对象时,会检查客户端是否已经打开;通过RPC与NameNode通信并创建新文件,构建出DFSOutputStream,该对象负责数据的写入
- 建立数据流pipeline管道:客户端得到一个输出流对象,通过调用*ClientProtocol.addBlock()*向NameNode申请新的空block,addBlock()会返回一个LocateBlock对象,该对象保存可写入的DataNode信息,然后构成pipeline
- 通过数据流pipeline写数据:当DFSOutputStream调用wirte()方法写入数据时,数据会先被缓存在一个缓冲区中,写入的数据会被切分为多个数据包,每达到一个数据包长度(65536Byte)时,DFSOutputStream会构造一个Packet对象保存当前要发送的数据包;新构造的packet对象则被放到DFSOutputStream维护的dataQueue队列中,DataStream线程会从dataQueue队列中取出packet对象,通过底层IO发送到pipeline中的第一个DataNode,然后第一个DataNode发送至第二个DataNode,以此类推。发送完成后该packet被移出dataQueue,并放入DFSOutputStream维护的确认队列ackQueue中,当收到所有DataNode的确认消息后,移出确认队列。(注:Chunk是Client向DataNode或者DataNode pipeline之间进行数据校验的基本单位,默认为512Byte,带有4Byte的校验位,因此实际上每个Chunk写入packet的大小为516Byte)
- 关闭输入流并提交文件:客户端完成整个文件中所有数据块block的写操作后,调用close()方法关闭输出流,然后调用*ClientProtoclo.complete()*方法通知NameNode提交该文件的所有block,NameNode确认该文件的备份数是否满足要求。